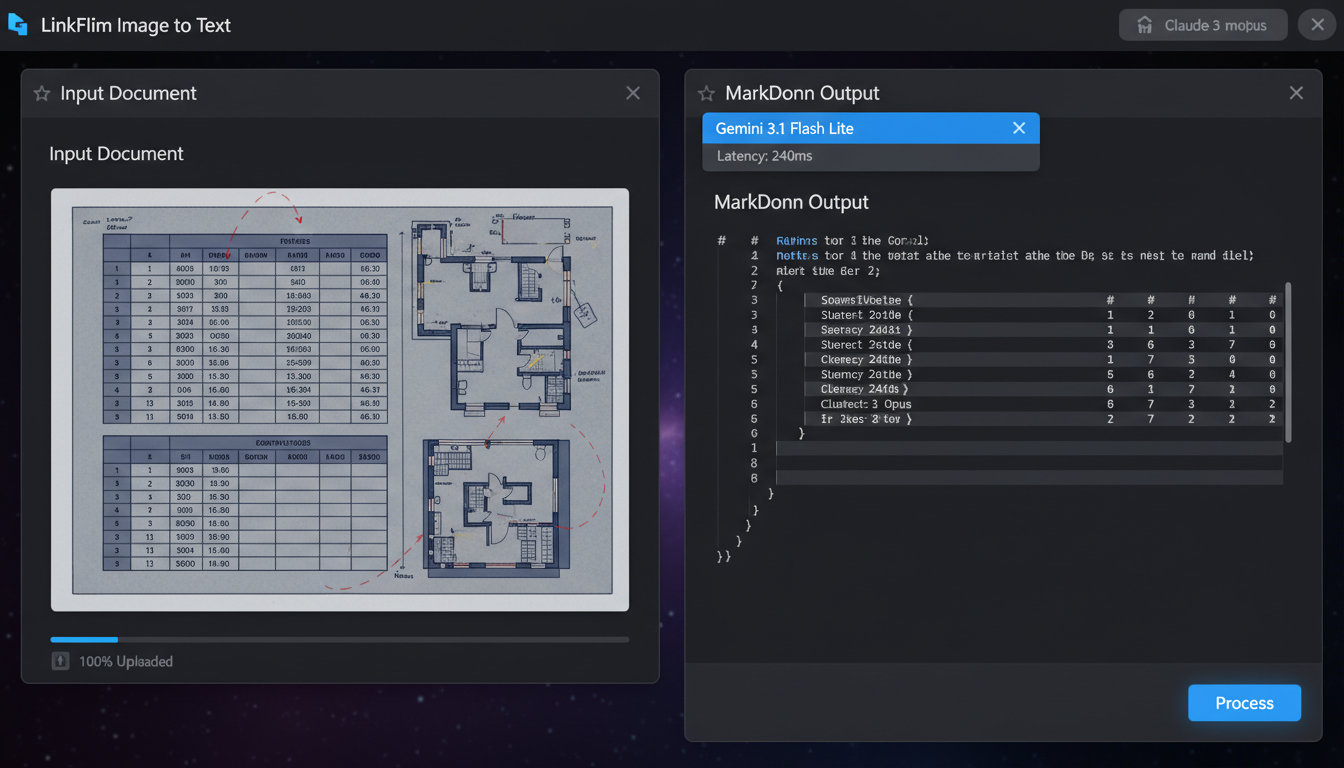
VLM Text Extraction: Preserving Document Layout Hierarchies

Beyond Legacy OCR: How VLMs Read Images
Direct Answer: VLM Image to Text is a spatial-aware vision-recognition technology that uses multimodal Visual Language Models to analyze, interpret, and extract text from static images. Unlike traditional OCR engines that scan raw pixels line-by-line, a VLM-driven pipeline treats the entire document as a holistic visual scene, preserving multi-column layouts, nested tabular data, and hand-drawn script hierarchies simultaneously.
The Reading Order Problem: Why Layout Preservation Matters
Traditional character recognition engines are highly rigid. When encountering multi-column PDFs, side-by-side tables, mixed font families, or low-contrast hand-drawn notes, standard scrapers parse text sequentially from left to right, completely scrambling the reading order and layout logic.
By shifting to a vision-first framework, the extraction process transitions from raw character scanning to holistic semantic comprehension. Instead of dumping scrambled, single-column text blocks, a VLM-driven extraction maintains the spatial relationships of your document, ensuring that tables, columns, and handwritten notes are structured into copy-ready Markdown or clean tabular outputs on the fly, saving hours of manual restructuring.
Core Workflows for High-Density Extraction
Advanced visual-language processing maps natively across several fast-growing enterprise and creative workflows:
- High-Density Document Parsing: Instantly digitize scanned multi-column invoices, layout grids, or complex data sheets while preserving horizontal column alignments and table borders.
- Handwritten Recognition & Translation: Convert handwritten whiteboard sessions, designer notebook entries, or printed notes in multiple font families and global languages (including Bengali, Chinese, and European dialects) into clean digital string arrays.
- Dynamic Alt-Text & Reverse-Prompting: Automatically generate detailed, context-aware alt text descriptions for accessibility compliance, or reverse-engineer existing graphical assets into descriptive prompt scripts for image-generation nodes.

Current Technical Constraints of Vision Parsing
- Dependent on Input File Contrast: Extremely low-resolution, blurry, or highly shadowed input files can result in minor semantic estimation errors during handwriting parsing.
- Higher Processing Latency: Performing deep document reasoning using frontier vision models requires more compute resources and slightly higher latency than running a flat, legacy OCR character scanner.
Why Choose LinkfilmAI Image to Text?
Standard scraper tools struggle with complex multi-column grids, break under hand-drawn fonts, and force you into rigid, high-latency pipelines. LinkFlimAI completely reimagines document extraction on an open canvas:
- Smarter Layout Processing: LinkFlimAI respects the grid. Instead of dumping scrambled, single-column text blocks, our VLM node respects the original reading hierarchy and layout architecture of your visual inputs.
- Granular Model Selection: We don't lock you into a single pipeline. Our visual canvas lets you select your processing engine—such as routing lightweight extractions through Gemini 3.1 Flash Lite for immediate, low-latency execution.
- Clean Export Pipelines: Instantly download parsed text in clean formats (like .txt or .docx) or copy it directly to your active clipboard, bypassing the messy encoding corruptions common in legacy parsers.