VLM Image to Text: Layout-Preserving AI Extraction at Scale

What is Image to Text?
Direct Answer: Image to Text is an AI-powered vision-recognition technology that uses Visual Language Models (VLMs) to analyze, extract, and convert text from static images into editable digital formats. Utilizing multi-layered neural networks, modern Image to Text pipelines go beyond character matching to understand spatial document layouts, nested tabular data, and hand-drawn script hierarchies simultaneously.
The Shift: Moving From Brittle OCR to Structural VLMs
Legacy OCR engines are highly rigid, failing whenever they encounter multi-column layouts, mixed fonts, or low-contrast backgrounds. By leveraging a vision-first framework like Gemini $3.1$ Flash Lite, the extraction process transitions from raw pixel scanning to holistic semantic comprehension.
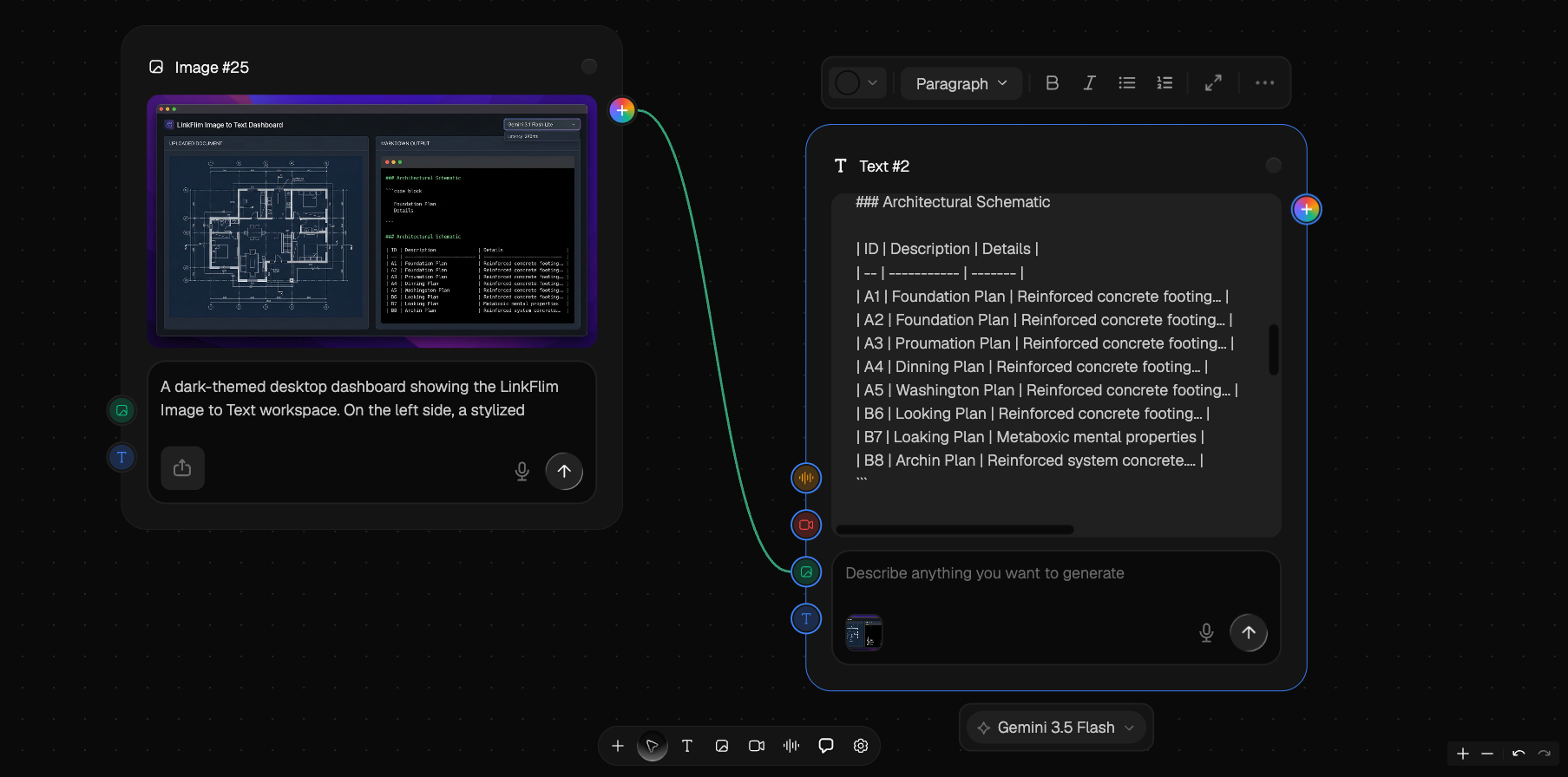
By utilizing streamlined vision-reasoning models, the platform achieves over structural parsing accuracy on complex documents without requiring manual post-processing or programmatic cleanup loops.
Core Production Use Cases
Optimizing your workflow with LinkFlim's VLM engine accelerates output across two primary engineering and creative vectors:
1. High-Density Layout & Document Ingestion
Instantly process scanned multi-column invoices, layout grids, or handwritten whiteboard briefs. The engine natively isolates text blocks, preserves horizontal tabular alignments, and converts the structured content straight to copy-to-clipboard, TXT, or markdown schemas.
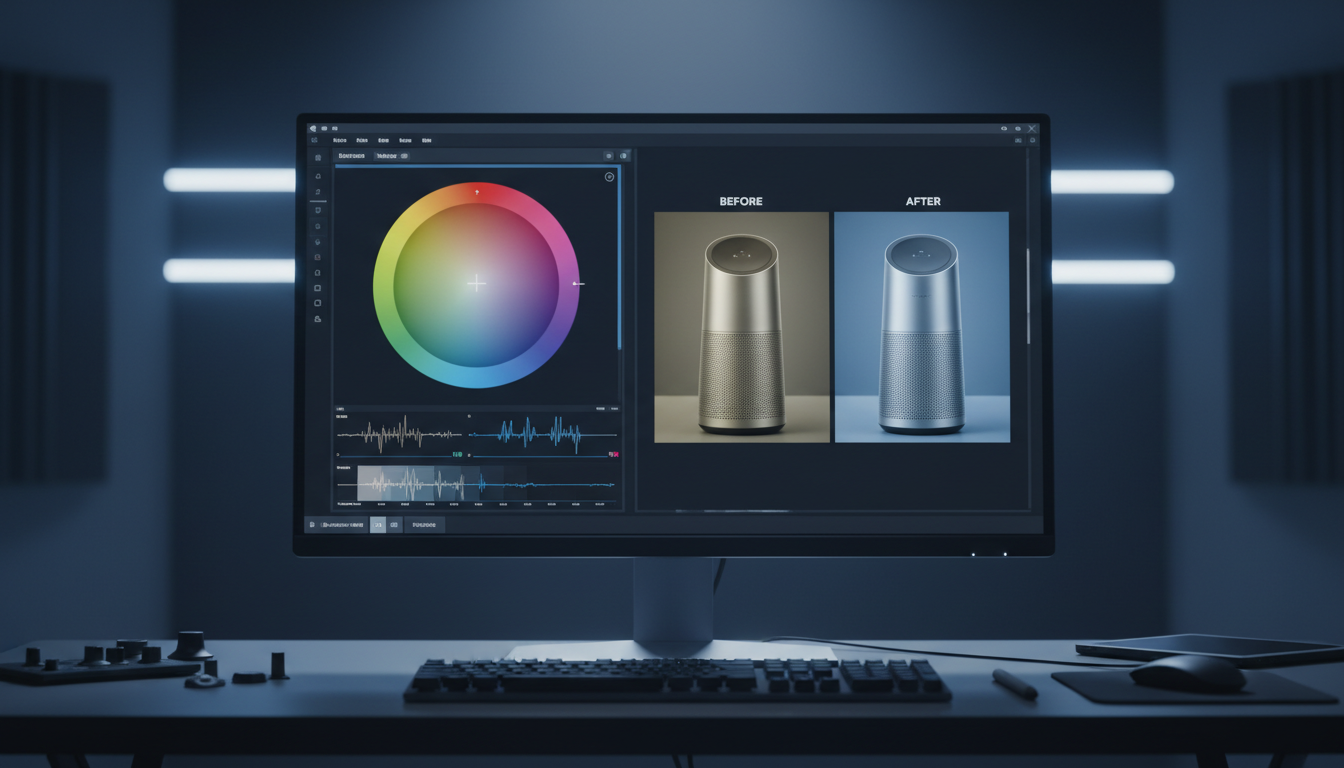
2. Creative AI Reverse-Prompting
Transform any existing graphical asset, portrait, or product photo into detailed, syntax-accurate text prompts. Creative directors can drop reference images into the canvas, extract their specific stylistic parameters, and instantly map the output to generate exact, scaled variations across visual production tools.
.png)
How It Works Natively
The LinkFlim platform abstracts complex visual-language pipelines into a frictionless, three-step client journey:
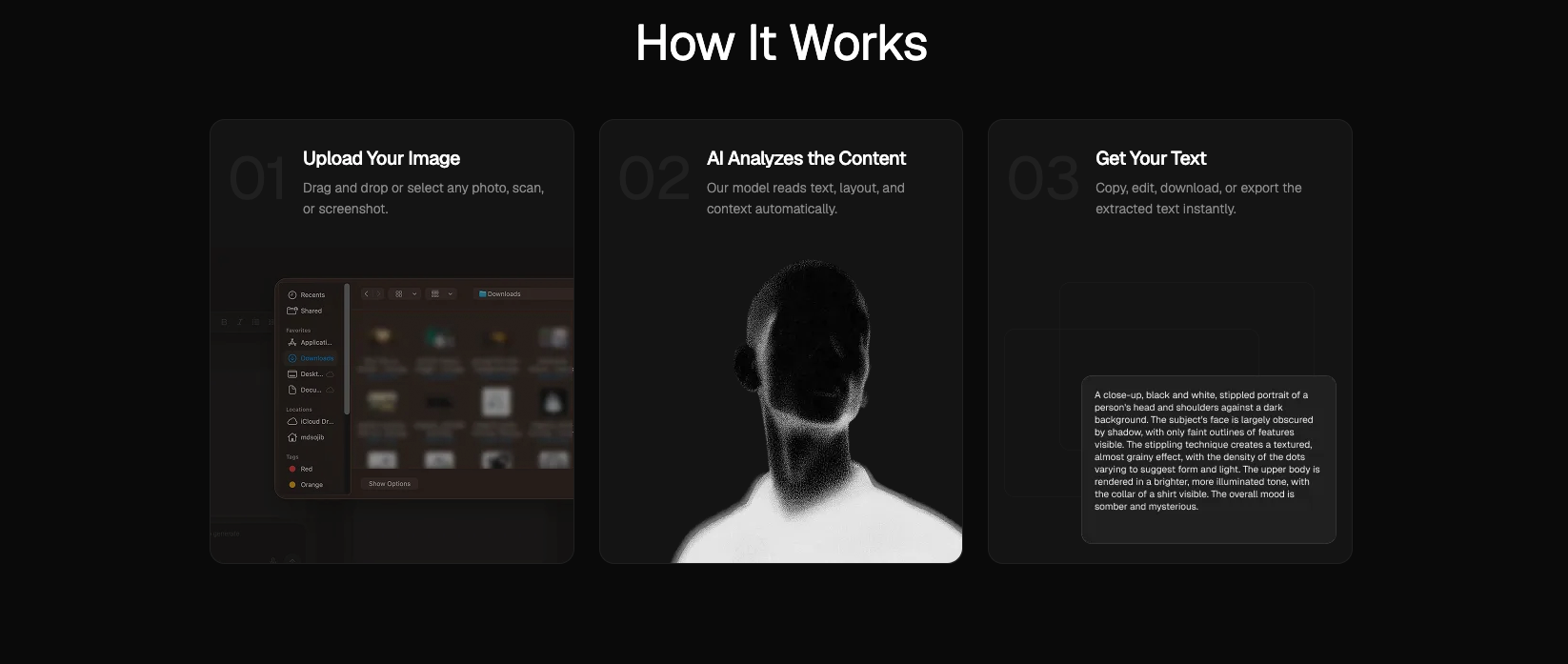
- Upload Your Image: Drag and drop any photo, mockup, or multi-column scanned PDF natively into the workspace.
- AI Analyzes the Content: The VLM analyzes spatial orientation, nested tables, hand-drawn typography, and global context automatically.
- Get Your Text: Instantly copy, download, or export structured text formats directly to your developer repository or active clipboard.
Why Choose LinkFlim AI?
Standard text extraction tools struggle with multi-turn revisions, break under compound layouts, and force you into a single, high-latency pipeline. LinkFlim completely reimagines this document workflow:
- Smarter Layout Processing: Unlike standard scrapers that scramble side-by-side columns, LinkFlim respects the tables, grids, and original hierarchy of your files.
- Granular Model Selection: Choose your speed-to-intelligence ratio. Deploy lightweight pipelines like Gemini $3.1 Flash Lite for immediate extractions, or scale up to frontier reasoning engines for heavy research datasets.
- Seamless API Integrations: Export clean, validated text strings directly to your active production environment without dealing with formatting corruptions.
Stop letting valuable structured data remain locked inside static graphics. Leverage the speed, precision, and multi-model intelligence of LinkFlim to streamline your production environment today.