Video Upscaler: Neural Super-Resolution

Defining Video Upscaler Architecture
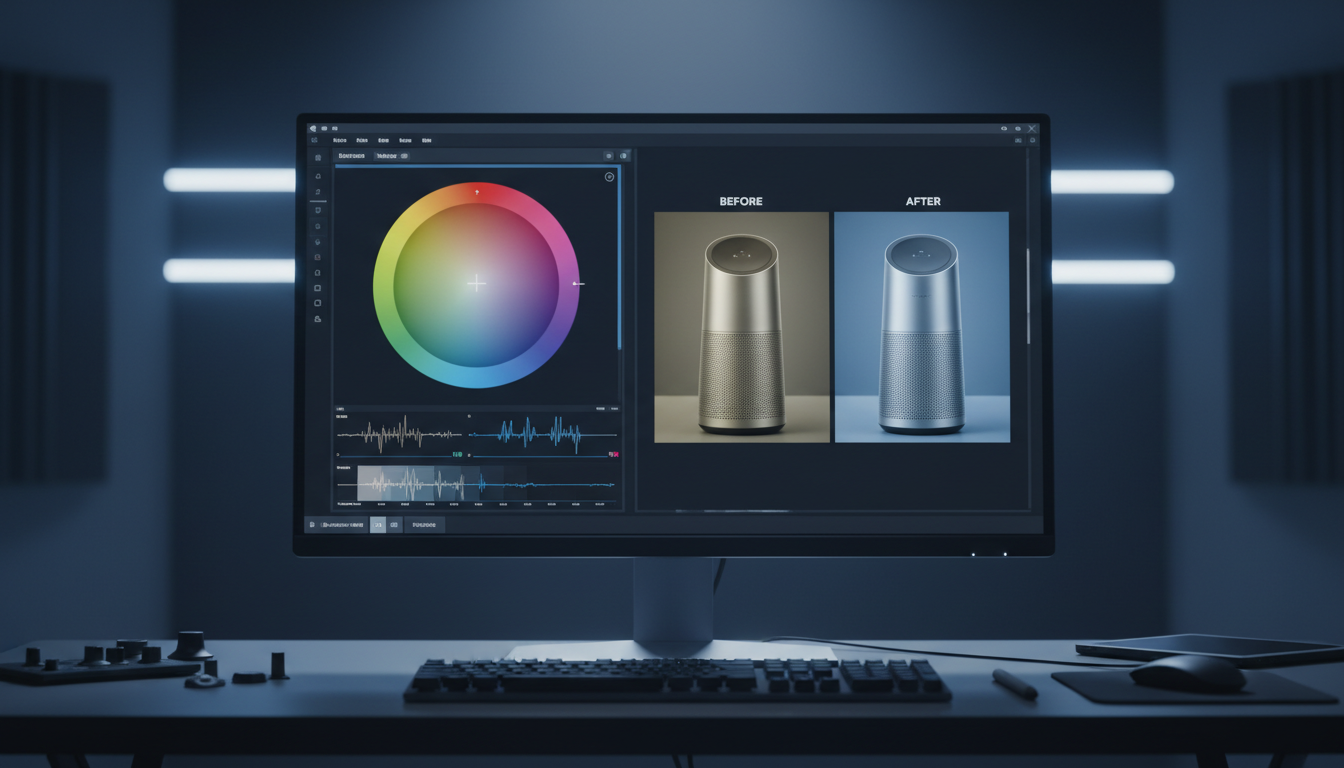
Direct Answer: Video Upscaler is a neural super-resolution technology that utilizes generative diffusion models to increase the frame resolution of existing video files. Unlike legacy bicubic interpolation that stretches pixels, this system analyzes the underlying geometry and material textures of the frame to mathematically reconstruct high-frequency details, sharp edges, and authentic surface clarity.
The Resolution Bottleneck: Why Standard Upscalers Fail
Standard editing software uses linear interpolation to "resize" video. When you blow up a 1080p clip to 4K using basic tools, the software simply guesses what the empty spaces between pixels should look like, resulting in a soft, "smeared" image. To make matters worse, these tools often ignore the time dimension, creating jitter or "swimming" artifacts across consecutive frames.
Advanced Video Upscalers resolve this by utilizing temporal-aware super-resolution. By training on massive datasets of high-definition footage, these models understand how textures should behave across time. Instead of blurring the image, they "predict" and regenerate fine-grain structures—such as skin pores, fabric weaves, or metallic reflections—ensuring the upscaled output looks like it was captured in native 4K or 8K resolution.

Core Use Cases for Video Upscaler
The Video Upscaler family enables three high-value workflows for technical creative teams:
- Archival & Legacy Restoration: Instantly bring legacy footage, low-bitrate captures, or archival projects up to modern high-definition standards, removing compression noise and restoring image sharpness.
- Multi-Source Standardization: Seamlessly combine footage from diverse sources—ranging from smartphone captures to cinema-grade cameras—into a single, cohesive high-resolution master file.
- Post-Crop Clarity Recovery: Safely crop and reframe your video sequences for different social aspect ratios (e.g., 9:16 for stories) without sacrificing final image fidelity or edge clarity.
Technical Constraints of High-Resolution Models
While neural upscaling provides unmatched sharpness, users must consider the model's specialized operational boundaries:
- Computation-to-Resolution Scaling: Upscaling video is a massively parallel task. Because the engine must reconstruct high-frequency details for every individual frame while maintaining temporal consistency, it requires significantly more GPU compute power (VRAM) than static image upscaling.
- The "Noise-to-Detail" Trap: These models are highly sensitive to the quality of the input. If the source file is heavily damaged by severe compression (macro-blocking), the engine may occasionally struggle to distinguish between valid textural data and compression artifacts, requiring clean source inputs for the best results.

Why Choose LinkfilmAI for Video Upscaling?
We integrate professional-grade neural super-resolution directly into your node-based canvas, treating upscaling not as a final step, but as a dynamic asset to be refined.
Instead of treating your upscaled output as a static "closed" file, LinkfilmAI lets you route your enhanced video directly into downstream nodes. You can upscale your footage, then immediately run it through color-grading or stabilization nodes, keeping your entire creative workflow—from restoration to final master—contained within one high-efficiency platform.