Video Generation Tools: Cinematic Motion Synthesis

Defining Video Generation Architecture
Direct Answer: Video Generation Tools are sophisticated suites of multimodal generative video models engineered to synthesize realistic motion, cinematic lighting, and temporally stable video sequences from descriptive text, static images, or motion-brush inputs.
The Temporal Bottleneck: Why Standard Video Models Fail
Many generative video tools rely on simple frame-by-frame interpolation. If the model does not "understand" the physical permanence of an object, it will cause items to randomly vanish, morph into different shapes, or jitter inconsistently between seconds. This is known as "latent drift" in the time dimension.
Advanced video generators resolve this by utilizing deep-temporal transformer architectures. By training on massive datasets of film, animation, and real-world footage, these models develop an internal "physics engine" that tracks objects, lighting, and movement trajectories across the entire duration of the clip. This ensures that a character walking down a street remains the same character from start to finish, with realistic shadow behavior and consistent textural detail.

Core Use Cases for Video Generation
The Video Generation family enables three high-value workflows for technical creative teams:
- Cinematic Narrative Synthesis: Generate high-fidelity narrative b-roll, establishing shots, or character-driven sequences directly from detailed text prompts, streamlining the pre-visualization process.
- Motion Brush & Stylization: Apply specific directional movement to static assets using Motion Brushes, allowing users to animate specific elements (like flowing water, moving clouds, or walking subjects) within an existing image.
- Complex Multi-Asset Choreography: Direct complex camera movements and subject behaviors simultaneously, outputting polished video files that act as ready-to-use production assets for commercial and editorial projects.
Technical Constraints of High-Throughput Models
While generative video provides unmatched cinematic quality, users must consider the model's specialized operational boundaries:
- Temporal Inference Cost: Because the model calculates the physics and lighting of the entire video clip simultaneously, generative video requires significantly more compute (VRAM and TFLOPS) than static image generation, leading to longer processing queues.
- Strict Narrative Adherence: These models are powerful but "opinionated" in their interpretation of physics. Because they attempt to simulate realistic world behavior, users must provide highly specific narrative instructions—vague prompts can result in unpredictable, surreal physical behavior.
Why Choose LinkfilmAI for Video Generation?
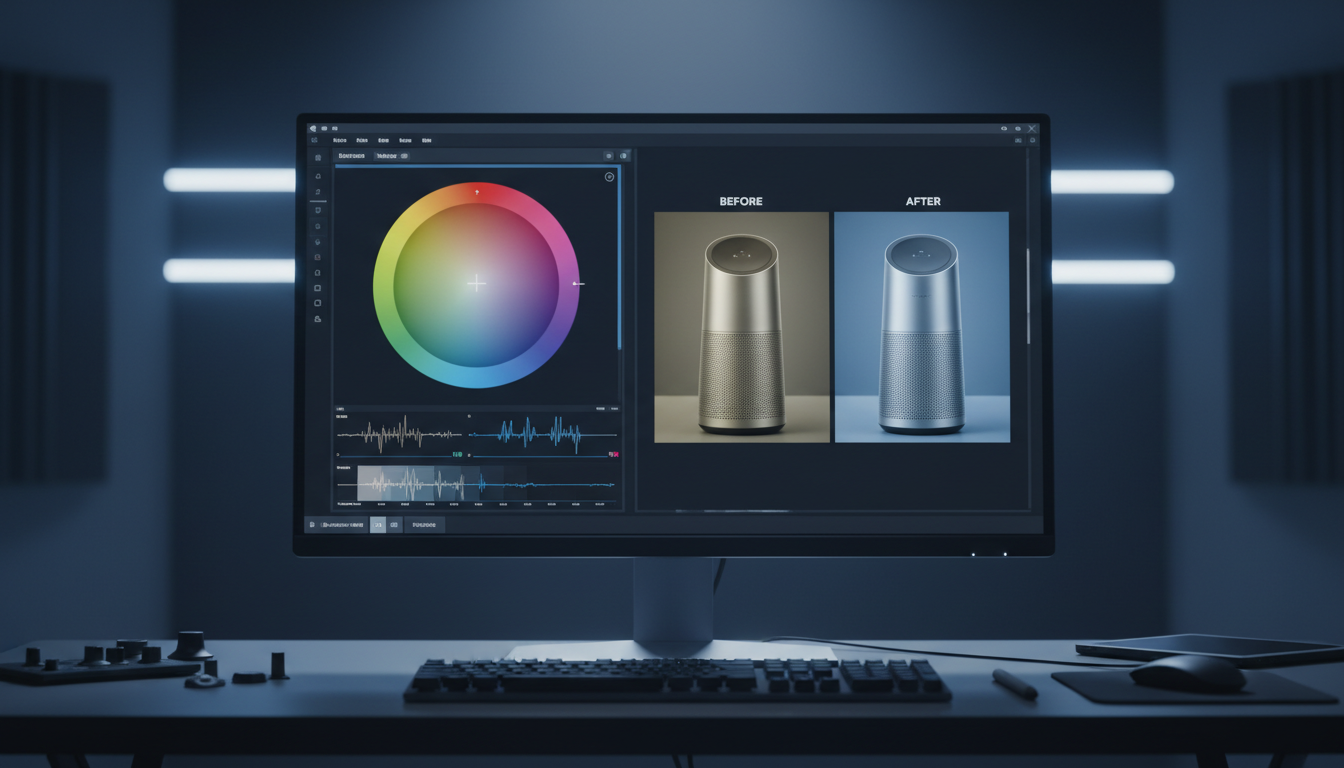
We integrate professional-grade video generation stacks directly into your node-based canvas, treating video not as a final export, but as a dynamic asset to be edited.
Instead of treating your video output as a static "closed" file, LinkfilmAI lets you route your video generations directly into secondary compositing nodes. You can take your generated video clip, run it through color-grading nodes, apply resolution-upscaling passes, and merge it with static overlays, keeping your entire cinematic workflow—from storyboard to final master—contained within one high-efficiency platform.