Minimax AI: High-Performance Multimodal Synthesis

Defining Minimax Architecture
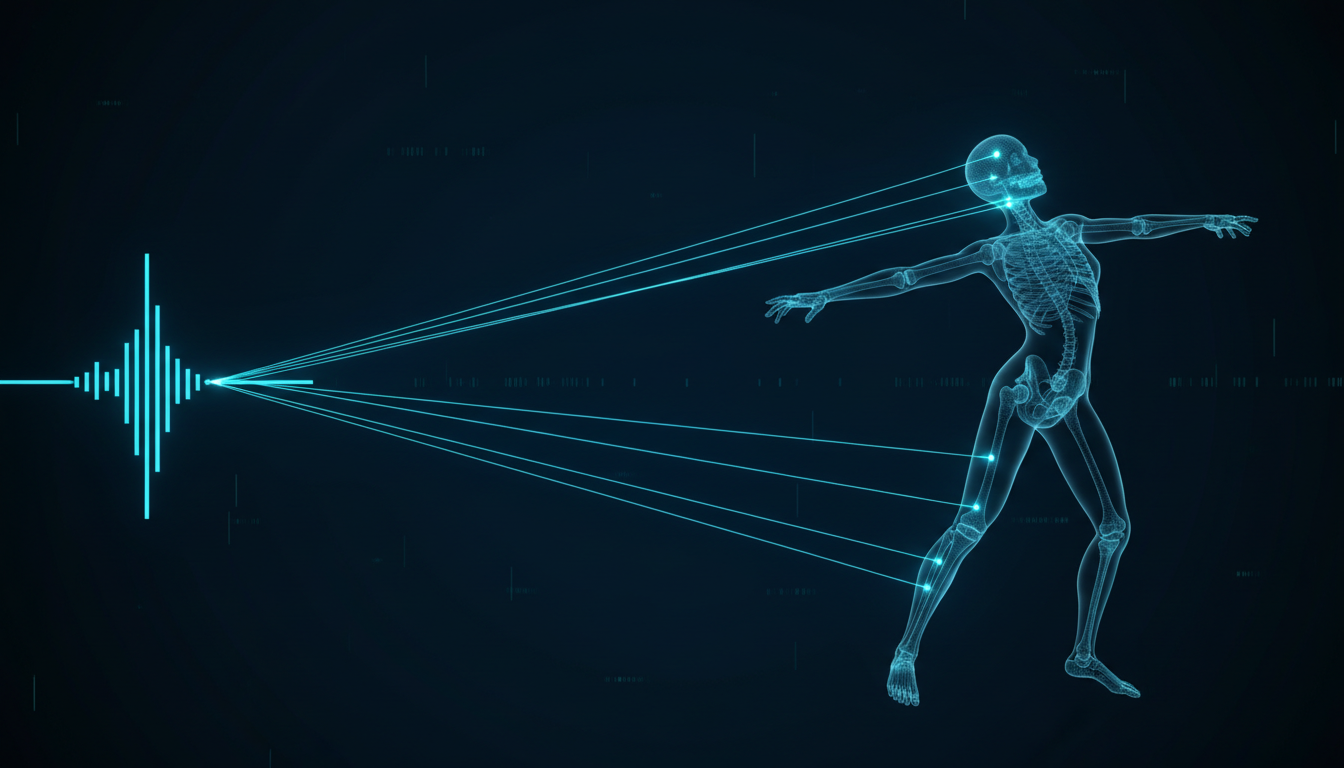
Direct Answer: Minimax AI is a natively multimodal generative platform engineered for the high-performance synthesis of synchronized audio and visual media. By leveraging cross-modal attention mechanisms, it enables the generation of aligned voice-overs, sound design, and character movement, ensuring absolute temporal coherence across every asset.
The Synchronization Bottleneck: Why Generalist Models Lose Focus
Most generative engines operate in silos: a model for image, a model for audio, and a separate logic for video. When you try to force these tools to work together, you encounter "pacing drift," where dialogue doesn't land on the visual beat and sound effects lack the physical weight of the scene. This forces creators into a manual "fix-it" cycle, attempting to glue together disparate files after the fact.
Minimax resolves this by prioritizing multimodal grounding. Because the engine perceives the temporal and spatial relationship between your narrative script and your visual sequences, it automatically synchronizes the pacing of your audio—from dialogue emotionality to environmental soundscapes—with the visual movement of the subject. This creates a predictable, deliberate cinematic flow where the sound design and visual storytelling function as a single, engineered pipeline.

Core Use Cases for Minimax Integration
The Minimax family enables three high-value workflows for creative production teams:
- Synchronized Narrative Synthesis: Generate video sequences with native, lipsynced dialogue and integrated foley effects, ensuring your story’s pacing is locked from the moment of generation.
- Unified A/V Prototyping: Explore complex subject-environment interactions where sound design reacts dynamically to visual changes, allowing for rapid iteration on scene-wide "mood" without secondary audio editing.
- High-Pacing Content Choreography: Synthesize intense, high-motion sequences that require tight temporal integration, such as character speeches in fast-moving environments or interactive musical presentations.
Technical Constraints of Multimodal Models
While Minimax provides unmatched temporal alignment, users must consider the model's specialized operational boundaries:
- Multimodal Compute Density: Because the model performs concurrent processing of video frames and high-frequency audio streams, achieving consistent, long-form multimodal output requires significant GPU compute headroom compared to unimodal generation.
- Instructional Narrative Depth: Minimax is highly responsive to detailed script and action briefs. Achieving the desired A/V rhythm requires clear, descriptive instructions regarding tone, voice inflection, and visual cadence; overly broad prompts can lead to unintended "drift" in the synchronization layer.
Why Choose LinkfilmAI for Minimax?
We anchor Minimax as the primary temporal orchestrator of your production workspace, ensuring your sound and narrative motion are perfectly bound.
Instead of treating your A/V assets as disconnected, separate imports, LinkfilmAI feeds your narrative briefs and static visual markers directly into the Minimax synthesis node. You route your script and visual intent into the same multimodal node, ensuring that your sound design, dialogue, and video pacing evolve simultaneously, creating a seamless workflow from storyboard to final cinematic export.